Everyday is a great day to learn something new…
Sometimes ago I had the incredible luck of supervising the installation of an “application-layer-firewall”.
It is, for those of you who never heard about it, a black-box device, usually using internally lots of open source software but nevertheless sold for big buck$, built to protect web server from being hacked. It achieves this goal by filtering all incoming HTTP requests (possibly outgoing responses, too), and blocking those that look suspicious enough / violate a defined set of rules.
Many of these devices offer a lot of extra functionality, such as providing HTTPS termination for those webservers that do not support it natively, rewriting of incoming requests etc… All in all, very useful boxes.
It is the very principle upon which they are built that left me baffled the first day we tried to configure ours, and it still has me unconvinced, namely that sloppy coding on part of the programmer can be overcome by adding an extra layer of black-box filtering that works without any knowledge of the functions implemented on the webserver.
I have been told umpteen times that the http firewalls follow the 80%/20% rule, warding off common attack vectors such as buffer overflows and escape sequences in urls, and this is useful enough by itself to justify their cost.
But in the modern-day internet, phising, xss and sql-injections attacks are more and more common, and while nobody is interested in defacing your site anymore, a lot of crackers are eager to get to your database where customer credentials are kept. And while http firewalls excel at the former, they are very poor at the latter.
This rant could go on forever, but basically in the end, for every bug left exposed by a web coder, a config. line, usually a regular expression (much harder to get right than a php function call), has to be input into the http-firewall by the sysadmin. Doesn’t look like a great advance, to me.
Without further ado, here’s the case in point – the daily wtf that started this post, having dawned on me only yesterday:
The firewall I had the pleasure to install provides a feature whereby the http header identifying the backend webserver is massaged into a custom header. This should have the security benefit of hiding from hackers the exact version of the software you are using, thus denying them immediate knowledge of the bugs exploitable on that particular revision of the platform.
A lot of security experts would sneer at this “security measure” (security by obscurity), but it is an extra step that most sysadmins use anyway, regardless of http firewalls, so we turned it on.
Every webserver we published on the internet via the firewall looks like this to the client:
Server: CHEPAG Server
Do you think its real nature is now protected? Guess what happens when a causal user asks for a web page that does not exist on the protected web server? Here’s what I got on mine:
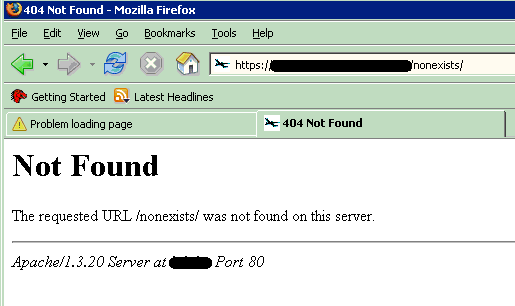
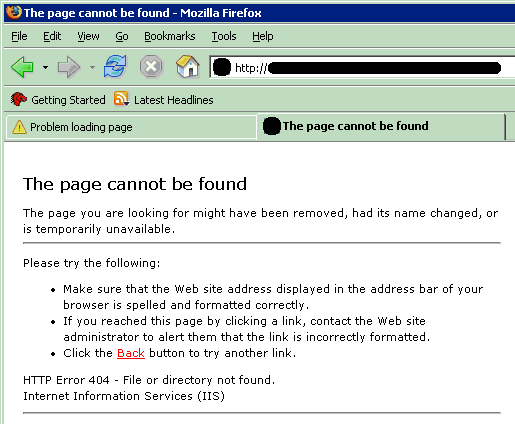
As you can see, not only it is trivial to identify the Apache powered website from the IIS powered one, but Apache is so gentle that it will reveal to everybody its version and the intranet server name.
Lest you start flaming me as incompetent sysadmin, I will say that yes, I know that both Apache and IIS provide means to alter the default error messages to anything that suits you best.
This just proves my point: there is little security added by the http-firewall, and the simplest and most effective security measures have to be taken on the webservers themselves.